Python is slow. It’s still faster than a lot of other languages, but describing Python code as “fast” will probably get some weird looks from people who use compiled or JITted languages.
Still, I love Python for its design and speed at which I can write good code. Most of the time, when writing Python for distributed or web applications, it doesn’t matter. Your runtime is usually dominated by network traffic or data accesses than it is by raw computational speed. In those cases, the correct optimization is often reducing network requests or indexing your data.
Sometimes—just occasionally—we actually do need fast computation. Traditional Python wisdom has been to profile your code (perhaps using cProfile), identify the hot spot, and rewrite it in C as a Python extension. I’ve had to do that before for a handwriting recognition algorithm with great success (it turned a 2–3 second computation into a practically real-time one), but writing C code and then figuring out the FFI was a pain. I had to rewrite the algorithm in C, verify that my C version was correct and didn’t have memory errors, and then figure out the right incantations to get it to cooperate with Python.
Let’s try something different this time.
Problem
At DoubleMap, geographic distance calculation is something that gets used a lot, and we use the haversine function to calculate distance between two points on Earth. In some of our data analysis, we might run the haversine function millions of times in a tight loop, and it was causing some reports to take way too long.
Profiling the code showed that the two heaviest operations were fetching data from the data store and the haversine function.
Play along at home: Clone the repo at https://github.com/doublemap/haversine-optimization and start from the first commit to see how the code changes step by step.
The commands you should know are pip install cython and python setup.py
build_ext --inplace.
Original code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Also, here’s the benchmark code that is used throughout:
1 2 3 4 5 6 | |
Pretty straightforward. Let’s try pre-compiling this code into a C extension to see if that helps.
Following the
Cython Basic Tutorial,
I renamed haversine.py to haversine.pyx and created a setup.py file:
1 2 3 4 5 6 | |
Running python setup.py build_ext --inplace built haversine.so out of my
unmodified Python code. Easy-peasy.
Benchmark results (300,000 iterations):
Original code: 2.85 seconds
Compiled: 2.01 seconds
So, 29% time savings without any modification to the original code.
C math functions
Currently, we’re still using Python’s math functions. Let’s see if we can cut
out some overhead by importing math.h instead.
Except, since this is Cython, all we need to do is:
1 2 3 4 5 | |
Benchmark results (300,000 iterations):
Original code: 2.85 seconds
Compiled: 2.01 seconds
libc.math: 1.33 seconds
So far we’ve saved 53% of the time from the original code.
C types
Cython’s biggest extension of the Python language is its type annotations. Speed ups can be had by telling Cython the types of each variable in advance. We are dealing with geographic coordinates, so we’ll be using doubles for pretty much everything:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Original code: 2.85 seconds
Compiled: 2.01 seconds
libc.math: 1.33 seconds
C types: 0.466 seconds
In three easy steps, we’ve reduced the run time of this function by 84%. More importantly, we’re still writing what’s basically Python. We don’t have to remember to free our variables or check our array bounds. That additional safety is not free (and there are various flags to disable Cython safety checks) but with Cython, optimizing a Python function doesn’t have to be a rewrite-everything task.
We probably could have gone further in optimizing this, but these speed-ups got us into “good enough” territory, and that’s good enough.
Distribution
Our optimized haversine function is available on PyPI under the name “cHaversine”. One key difference is that the distributed tarball includes the C code generated by Cython so that you, as the package user, don’t need Cython to download and build the C extension.
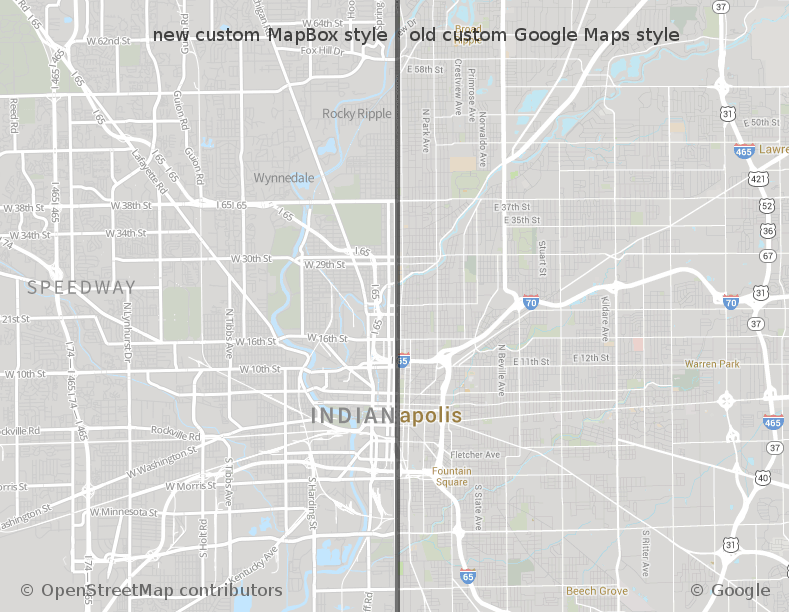
 This past week, we here at DoubleMap made a big change that users probably
won’t notice. Instead of Google Maps, all of our public maps are now powered
by MapBox with OpenStreetMap data.
This past week, we here at DoubleMap made a big change that users probably
won’t notice. Instead of Google Maps, all of our public maps are now powered
by MapBox with OpenStreetMap data.